Overview
The Quantized Transformer Language Model project is a groundbreaking initiative aimed at deploying large-scale Natural Language Processing (NLP) models on resource-constrained edge devices. By leveraging model quantization and optimization techniques, this project ensures efficient, low-latency inference while maintaining high accuracy. It integrates advanced Machine Learning (ML), Quantization, and TinyML frameworks to enable large transformer-based models like MobileBERT to run seamlessly on low-power devices such as Raspberry Pi. This innovation bridges the gap between cutting-edge NLP capabilities and practical deployment in embedded systems, offering privacy-preserving and resource-efficient solutions for real-time applications.
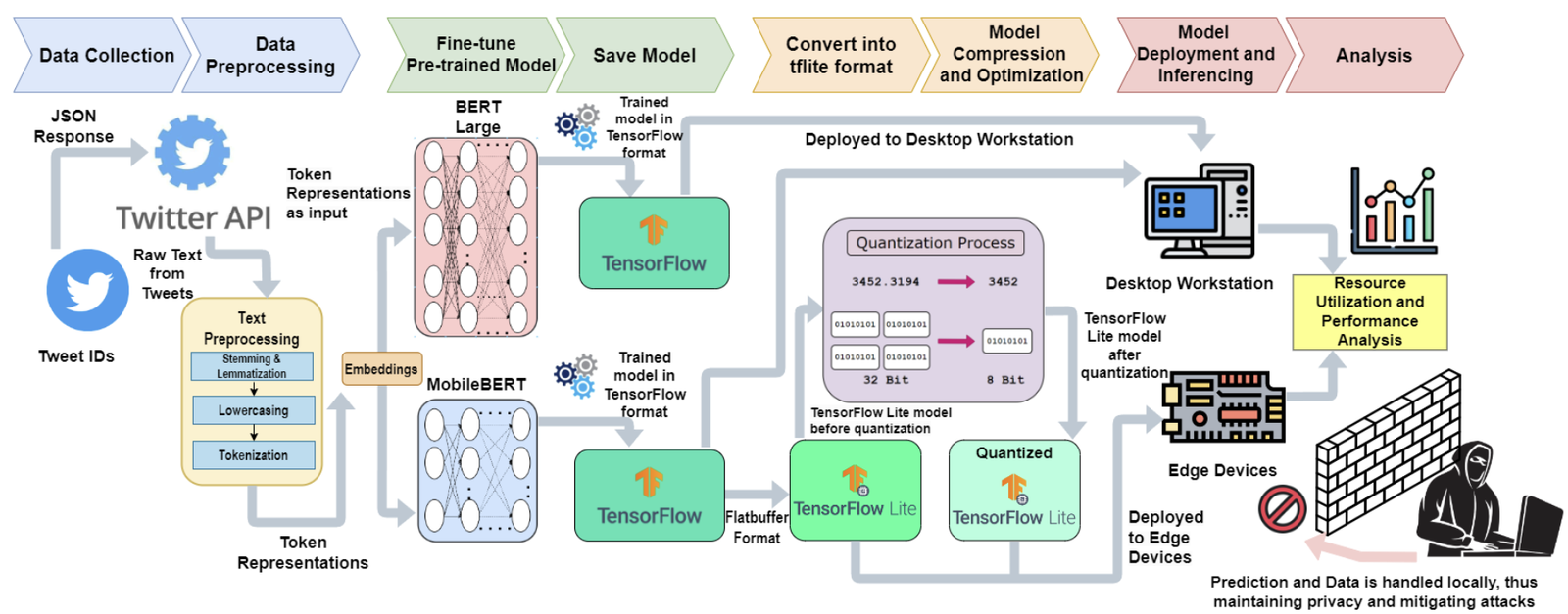
Fig: Framework for Resource Usage Analysis of Quantized Transformer Models
System Architecture and Workflow
- Data Collection and Preprocessing Phase
- Input: English tweets from the RepLab 2013 dataset and real-time user queries via APIs.
- Processing:
- Text cleaning and normalization to remove redundant spaces, symbols, and punctuation.
- Tokenization using BERT-compatible tokenizers.
- Output: Preprocessed, tokenized datasets ready for model fine-tuning and evaluation.
- Model Fine-Tuning Phase
- Core Model: BERT Large and MobileBERT.
- Processing:
- Fine-tune the models on reputation polarity classification tasks using preprocessed datasets.
- Optimize MobileBERT for downstream tasks using knowledge distillation and transformer embeddings.
- Output: Pretrained and fine-tuned models for multiclass classification based on reputation polarity.
- Quantization and Optimization Phase
- Core Techniques:
- Dynamic Range Quantization (DRQ) for reducing model size and computational overhead.
- Conversion of MobileBERT models to TensorFlow-Lite format using TensorFlow-Lite Converter.
- Processing:
- Post-training quantization to optimize weight representations and compress model size by up to 75%.
- Export models in TensorFlow-Lite FlatBuffer format for embedded system deployment.
- Output: Lightweight, optimized TensorFlow-Lite models in 32-bit, 16-bit, and 8-bit quantized versions.
- Core Techniques:
- Deployment Phase
- Hardware: Raspberry Pi 3B, 3B+, and 4B.
- Processing:
- Deploy TensorFlow-Lite models on edge devices using the TensorFlow-Lite interpreter.
- Perform inference tasks for reputation polarity classification in real-time.
- Output: Resource-efficient, on-device predictions without the need for server-based processing.
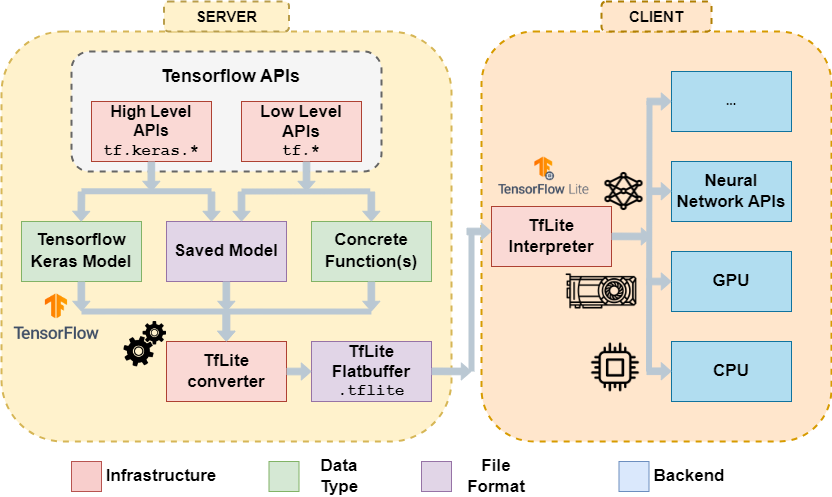
Fig: TFlite Model Conversion and Deployment
- Performance Evaluation Phase
- Metrics:
- Speed Index (SI): Measures inference speed and efficiency.
- Model Performance Index (MPI): Evaluates accuracy and F-Score relative to energy consumption.
- Resource Efficiency Ratio (RER): Quantifies CPU, memory, and power efficiency.
- Output: Detailed insights into model performance, resource usage, and energy efficiency across different devices and quantization levels.
- Metrics:
Key Features
- Efficient Model Deployment: Runs large transformer models on low-power edge devices without compromising accuracy.
- Quantization and Compression: Reduces model size by up to 160× through DRQ techniques.
- Real-Time Inference: Achieves at least one prediction per second, meeting real-time application requirements.
- Privacy-Preserving Framework: Ensures all data processing is performed locally, eliminating server dependency.
- Comprehensive Evaluation: Introduces novel metrics (SI, MPI, RER) for assessing speed, performance, and resource utilization.
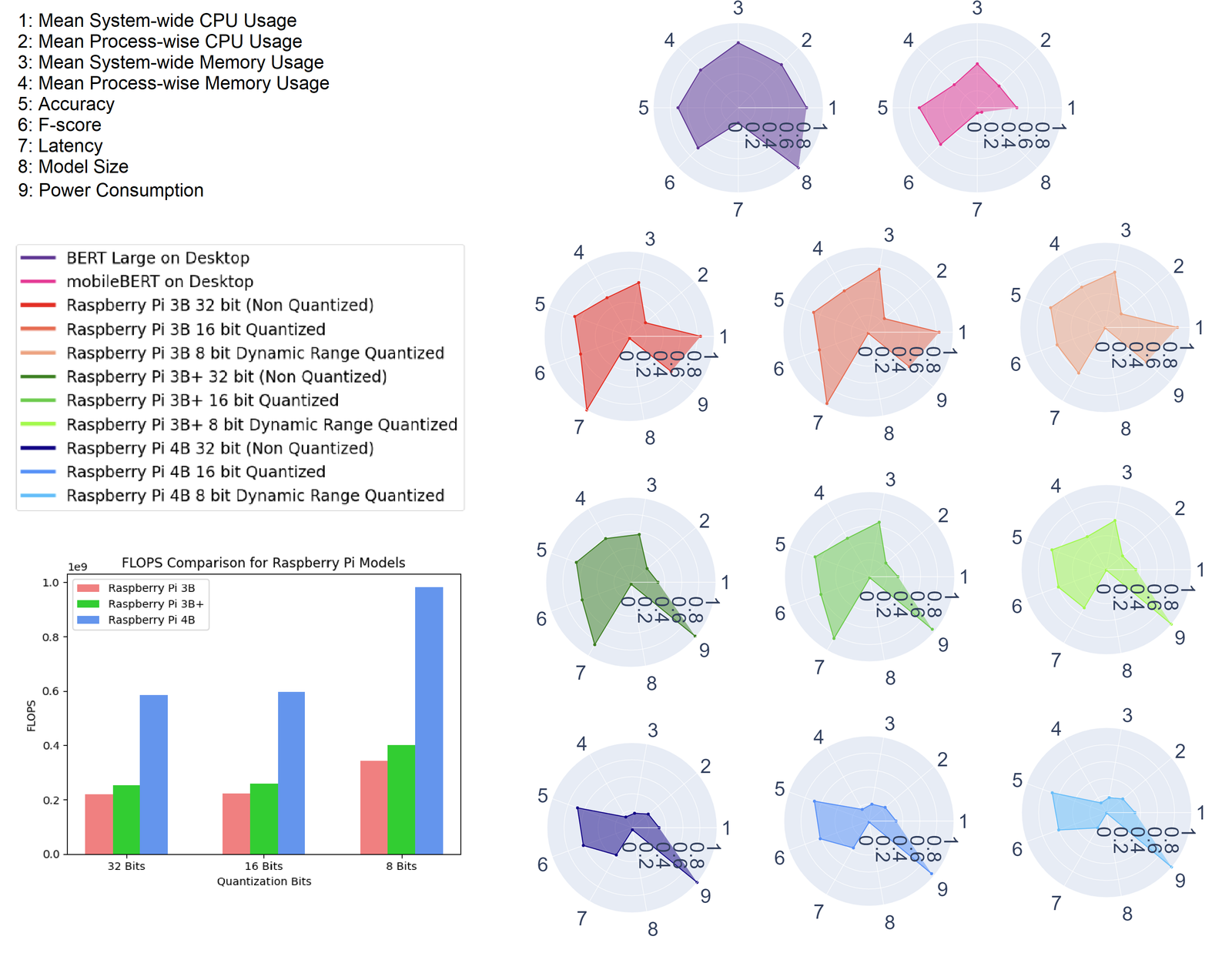
Fig: Comparative Analysis of the deployed models
Tools and Technologies
- Natural Language Processing: BERT Large, MobileBERT for reputation polarity classification.
- Quantization: TensorFlow-Lite for DRQ and model conversion.
- Edge Devices: Raspberry Pi 3B, 3B+, 4B.
- Resource Monitoring: PSUTIL for CPU and memory utilization, ACS712 sensor for power measurement.
- Programming and Platforms: Python, TensorFlow-Lite, TensorFlow.
Outcomes and Impact
- Performance Improvements:
- Achieved at least 4.1% drop in accuracy for a 160× reduction in model size.
- Delivered over 1 prediction per second on all quantized 8-bit models.
- Improved resource utilization across all tested Raspberry Pi models.
- Business Benefits:
- Provides a scalable framework for deploying NLP models on IoT devices and embedded systems.
- Enhances user privacy by enabling serverless, on-device data processing.
- Reduces infrastructure costs by minimizing hardware and energy requirements.
- Scientific Contributions:
- Introduced novel evaluation metrics (SI, MPI, RER) for holistic model assessment.
- Demonstrated the feasibility of running transformer-based models on edge devices with minimal resource consumption.
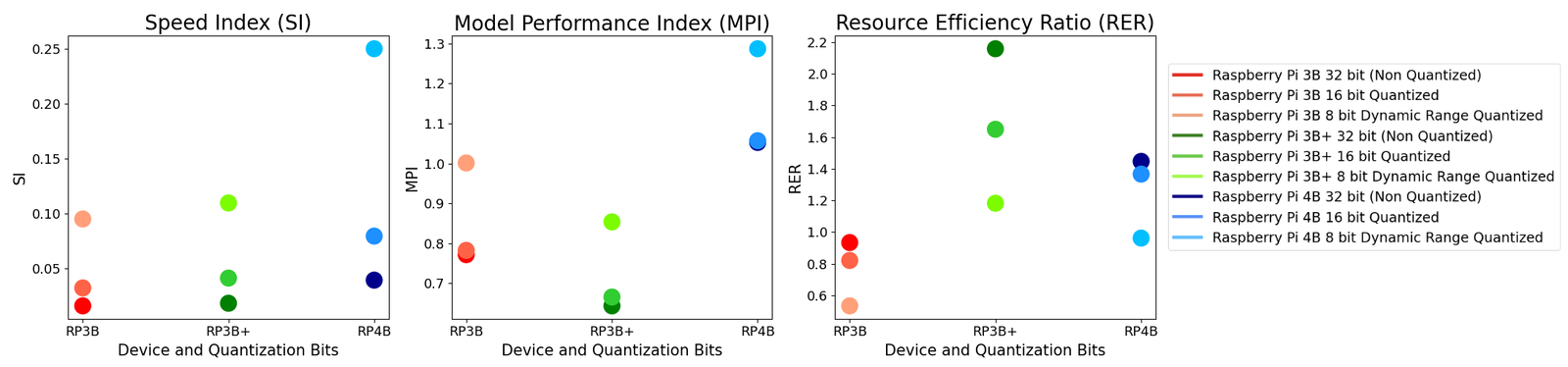
Fig: The SI, MPI, and RER values of the deployed models
The Quantized Transformer Language Model project represents a significant advancement in enabling transformer-based NLP capabilities on edge devices. By combining quantization, optimization, and TinyML techniques, it lays the foundation for scalable, efficient, and privacy-conscious AI solutions in resource-constrained environments.