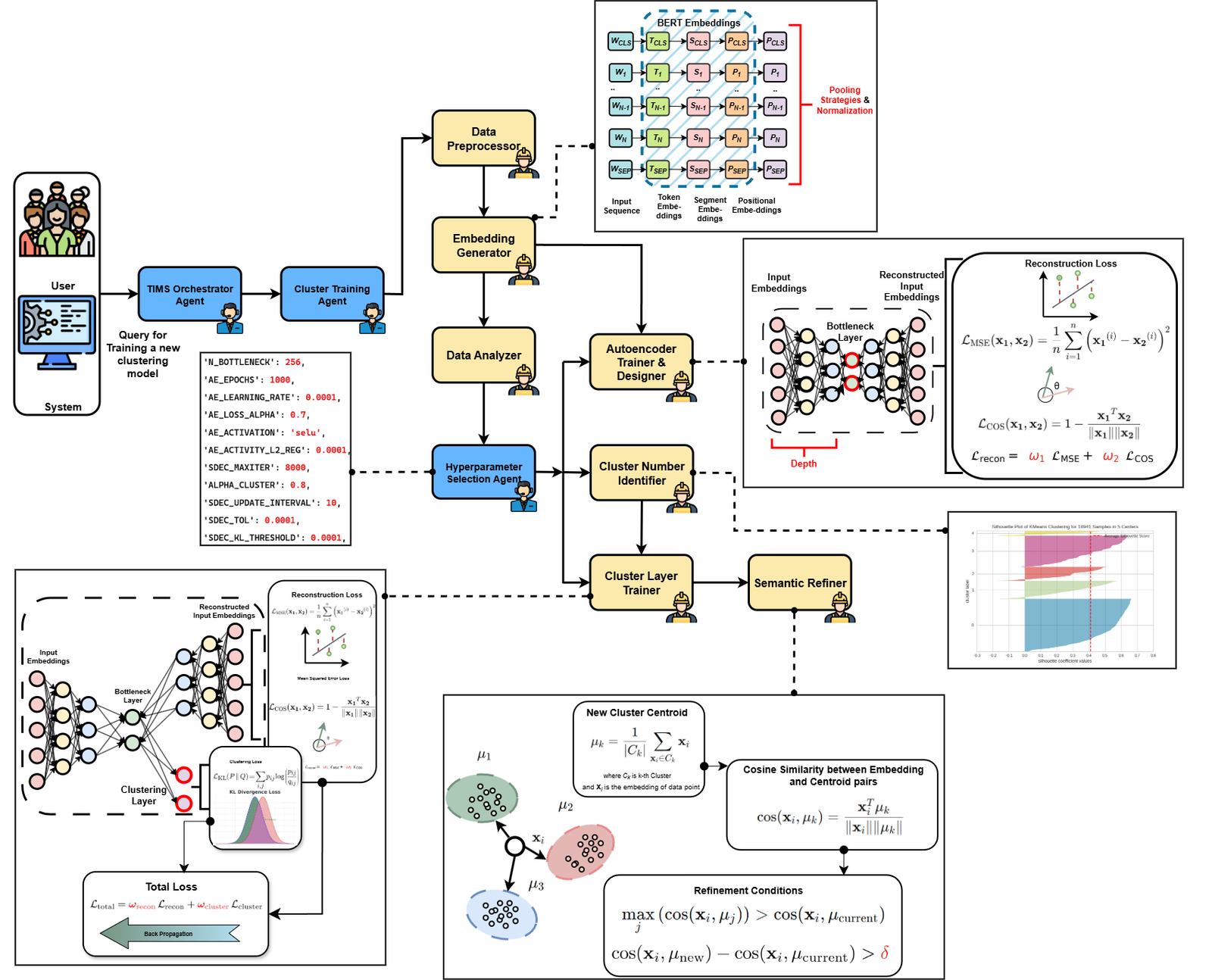
The Agentic Orchestration Based Scientific Research System (AOSRS) is a multi-agent, vector-driven orchestration framework designed to automate and intelligently manage scientific research workflows. It integrates retrieval-augmented generation (RAG), multi-level agent collaboration, and context-aware orchestration to streamline research processes—from literature retrieval and hypothesis formulation to result synthesis and reporting.
AOSRS employs a hierarchical agent architecture, where a central Orchestrator Agent governs the workflow lifecycle by coordinating subordinate agents and domain-specific worker agents. Through vector databases, AOSRS retrieves relevant workflows, pseudocode, or scripts based on user queries, enabling dynamic task decomposition and intelligent delegation.
The system ensures scalability, explainability, and reusability by maintaining context and artifact memory, which preserve results, manifests, and workflow metadata for future reference or replication. This makes AOSRS particularly suited for multi-domain scientific environments where complex analyses require multi-step reasoning, dynamic knowledge retrieval, and collaborative computation.

System Architecture
The AOSRS architecture is divided into several key components that interact through memory and orchestration planes:
1. Orchestrator Agent
- Acts as the central controller and entry point for user or system queries.
- Parses the research request and interacts with the Workflow Vector Database to retrieve relevant workflows or procedural templates.
- Builds up context memory by accumulating retrieved workflows, user history, and system metadata.
- Dispatches subtasks to subordinate agents while collecting and consolidating results.
2. Workflow Vector Database
- Stores indexed embeddings of workflows, pseudocode, and metadata.
- Uses an Embedding Model to semantically match user queries with similar research workflows.
- A Reranker Model further refines the retrieved results to ensure relevance.
- Enables retrieval of multi-step workflows, providing the Orchestrator with a structured plan for task execution.
3. Subordinate Agent Hierarchy
- Organized into Level 1 and Level 2 tiers for multi-step delegation.
- Level 1 Subordinate Agents interpret the orchestrator’s workflow segments and assign specialized tasks to worker agents.
- Level 2 Subordinate Agents further decompose substeps and manage their execution through Worker A–C, ensuring modular and parallel processing.
4. Workers and Agents Vector Database
- Contains embeddings and metadata of individual worker agents and code snippets (e.g., analytical modules, visualization scripts, or domain-specific solvers).
- Retrieved workers are chosen based on workflow requirements using a reranker model.
- Supports contextual multi-step retrieval, where workers can recursively reference previous steps or agents for context-aware task completion.
5. Worker Layer
- Domain-specific agents (e.g., Worker A–G) execute analytical or computational tasks.
- Workers produce results, manifests, or visualizations, which are stored in the Artifact Memory for traceability and reuse.
- Tasks may include data preprocessing, experiment simulation, model training, evaluation, or visualization.
6. TIMS Memory and Control Plane
- Serves as the operational backbone of the system.
- Tracks workflow states, manages run-time scheduling, consolidates worker results, and ensures versioned persistence in artifact memory.
- Provides a feedback loop to the Orchestration Core, enabling adaptive reasoning and iterative refinement across research tasks.
7. Artifact and Context Memory
- Context Memory: Preserves current and historical workflow contexts, allowing continuity across sessions.
- Artifact Memory: Stores tangible research outputs such as results, visualizations, and generated reports, forming a traceable research lineage.
End-to-End Flow
- A user submits a research query to the TIMS Orchestrator Agent.
- The Orchestrator retrieves and refines relevant workflows from the Workflow Vector DB.
- Appropriate subordinate and worker agents are selected from the Workers Vector DB.
- The agents collaboratively execute subtasks, guided by pseudocode and contextual embeddings.
- Results and artifacts are aggregated, stored in memory, and synthesized into a final scientific report.